
当社がリコメンドエンジンを提供しているOPTMS CONTENT(以下OPTMS)のアルゴリズムを解説する記事(3/3)です。
OPTMSでは記事だけでなく、記事に添える画像も販売しています。今回は画像の推薦について解説します。
 西尾 義英(ニシオ ヨシヒデ)
西尾 義英(ニシオ ヨシヒデ)データを活用できる製品・基盤づくりがテーマです。
記事と画像のマッチング
OPTMSの画面に表示される記事には全て画像がはめ込まれています。これは記事にもともと使われていた画像ではなく、株式会社アマナイメージズ(以下アマナイメージズ)が提供できるストックフォトから記事に合うものを探してはめ込んでいます。

方法
OPTMSで扱うストックフォトには全てキーワードが設定されています。第1回で述べたように、記事は単語の集まりとして数値のベクトルとして表されますから、キーワードを介して記事と画像を比較することができます。これにより、「最も記事に近い画像」を選ぶようにしています。
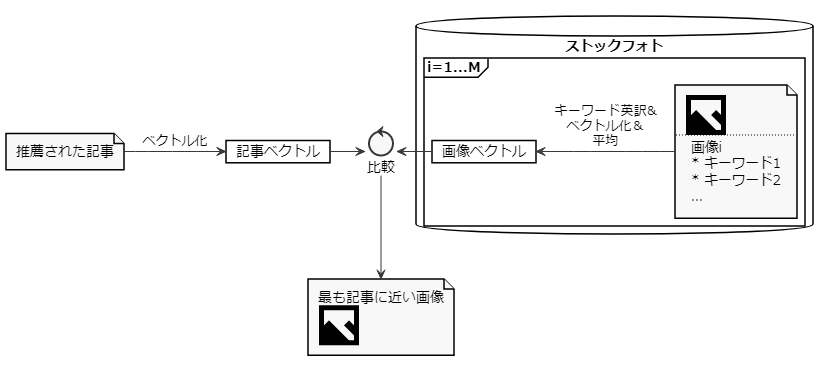
こんな方法で大丈夫か、最初は心配だったのですが「何となくどうしてその画像が選ばれたかわかる」という程度にはマッチしているようです。
ただ、この方法では異なる記事に同一の画像が選ばれる場合があり、推薦結果中の記事が重複しているように見えてしまう恐れがあります。これを避ける方法はいくつかありますが、現状は単純に「複数の記事間で割り当てられた画像が重複する場合、どちらかを記事ごと隠す」ことで対応しています(別途、記事毎に類似記事を提示できるのでこれで良しとしています)。
なお、記事に対する画像の類似度をまじめに計算すると記事数×画像数の計算が必要です。これを避けるために「近似最近傍探索」という技術を使っています。データベースのインデックスと同じノリですね。複数のアルゴリズムおよびオープンソースの実装がありますが、私たちが採用したのはYahoo! JAPAN研究所が公開しているNGTというライブラリです。NGTについては後述します。
もう一点補足すると、記事のベクトルは英語の単語ベクトルを元にしているので、画像のキーワードも全て英語に機械翻訳しています。逐語訳で十分なので、Googleの機械翻訳APIの安価な方(baseモデル)を使っています。
オウンドメディアと画像のマッチング
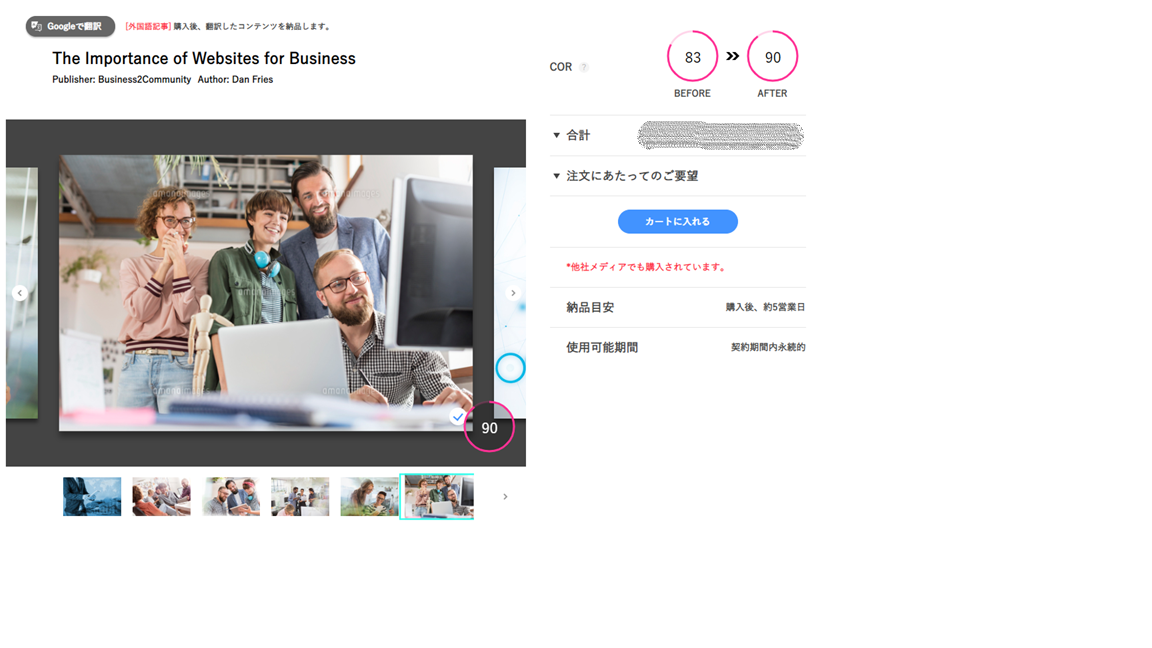
上で述べたのは、記事一覧において記事に似た画像を一つ選んで表示するということでしたが、その画像は差し替えることも可能です。ここで、下図右上に表示されている「COR」が83→90に向上していますが、これはユーザーにとっての画像の良し悪しが加点された結果です。
方法
キーワードによる画像のマッチングはどうやら使えそうだと分かったのですが、記事と画像の類似度を見るだけだとユーザーに最適化されているとはいえません。購入した記事・画像を掲載するオウンドメディアと、画像の一致度を加味することにします。メディアと画像の一致度を測る方法としては「テイストキーワード」に注目することにしました。これはアマナイメージズが提供しているEVEという画像検索ツールで使われているもので、「何となくこういうテイストの画像」を検索できるように設計されています。
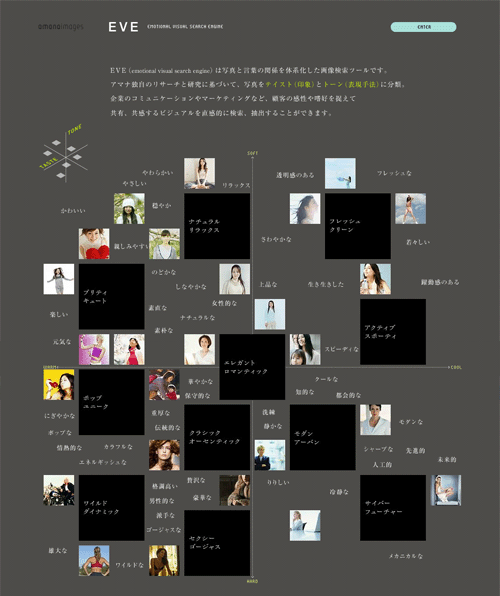
EVE: https://amanaimages.com/eve/
上の図では、「テイスト」の近い画像が近くに並んでいます。画像同士の一致度をこのように評価できるなら、画像とオウンドメディアについても同じことができそうな気がします。ただし、実装にあたっては以下の課題がありました。
- テイストキーワードの欠損。全ての画像にテイストキーワードが設定されているわけではない
- オウンドメディアのテイストを計算する方法。掲載された画像の情報を得るのが難しい
それぞれ以下のように解決することにしました。
1. テイストキーワードの欠損
テイストキーワードが無くても、(即物的な)キーワードは全ての画像が持っています。よって単純にテイストキーワードを普通のキーワードが予測できると考えました。
テイストキーワードの予測には、fastTextを使っています。Word2Vec を高速に計算できるライブラリですが、ラベル付けされた文章を学習して分類器を作る機能も持っているのでそれを活用しました。fastTextである必然性はありませんが、記事のベクトル化に使っている学習済みのモデルがfastText製だったので採用した次第です。
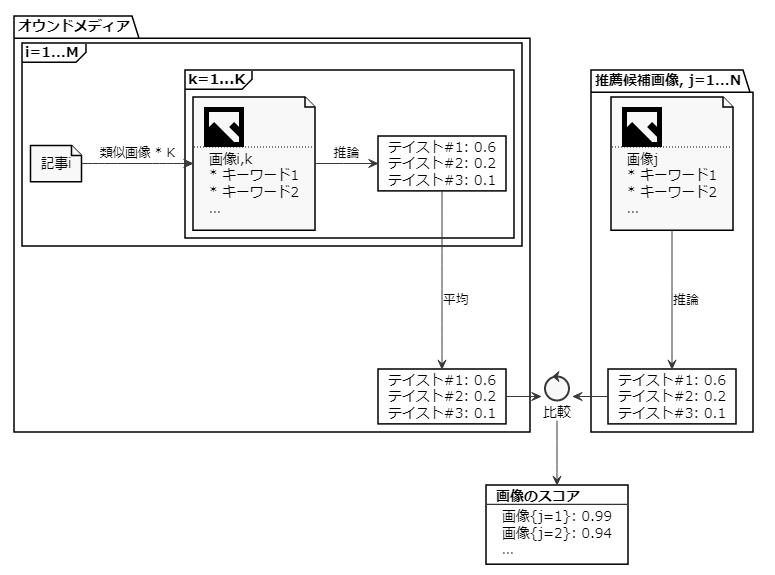
2. オウンドメディアのテイストを計算する方法
もし、オウンドメディアに掲載された画像が持つキーワードが分かれば1と同様にメディアのテイストが計算できるはずですが、実際に掲載された画像については未知である可能性が高いです。
画像については直接分からなくても、掲載された記事を知ることは簡単です。さらに、記事に似ている画像をストックフォトから選ぶことはでき、それらのテイストキーワードも推測可能です。下図のように、オウンドメディアからクロールした記事に似ている画像をそれぞれ数点ずつ抽出し、各画像のテイストキーワードの分布を平均すると、オウンドメディアのテイスト特徴が得られます。
ベクトル近傍検索
記事と画像のマッチングについて、記事と画像のベクトルを比較すると説明しましたが、これには記事数×画像数分の計算が必要となるため、任意の記事に画像をリアルタイムでマッチングさせることは難しいです。推薦する記事については日次のバッチ処理であらかじめ計算しておくこともできますが、OPTMSでは記事の検索も可能です。検索した記事に画像をマッチさせることも必要でした。調べた結果、「近似MIPSアルゴリズム」あるいは「近似最近傍探索」が求める手法だということが分かりました。
近似最近傍探索とは
近似最近傍探索とは、精度を少し犠牲にして、高速にベクトルを検索する技術です。ディープラーニングの流行とともに、画像や文書といった非構造データを数字の集まり(ベクトル、あるいはテンソルということもある)として扱うことが増えたからか、多くのアルゴリズム・ライブラリが提案されています。最近(2020/7/28)も、GoogleがScaNNというライブラリを自ら発表・解説する記事がありました。
この記事の中で、近似最近傍探索技術の重要性について、以下のように述べられています。
埋め込み(Embedding)に基づく検索は、単純なインデックス可能なプロパティではなく、意味の理解に依存するクエリへの応答に効果的な手法です。 このアプローチでクエリに回答するには、システムはまずクエリを埋め込み空間にマップする必要があります。次に、すべてのデータベース項目の埋め込みの中から、クエリに最も近いものを見つける必要があります。これは最近傍探索問題です。クエリデータベースの埋め込みの類似性を定義する最も一般的な方法の1つは、その内積です。このタイプの最近傍探索は、最大内積検索(MIPS)と呼ばれます。 データベースのサイズは数百万または数十億にもなる可能性があるため、MIPSは推論速度の計算上のボトルネックになることが多く、徹底的な検索は現実的ではありません。総当たりの検索を大幅に高速化するために、ある程度の精度を引き換えにする近似MIPSアルゴリズムが必要です。
~https://ai.googleblog.com/2020/07/announcing-scann-efficient-vector.htmlより、筆者翻訳 ~
アルゴリズム比較
この種のアルゴリズムを網羅的にベンチマークしているサイトがあります。
また、アルゴリズムの中身については、東大の松井先生がアルゴリズムの解説と共に手法の選び方を解説したスライドがあります。
その他、個人で比較しているブログもいくつかありました。総合的には以下が候補になりそうです。私たちは複数比較できなかったのですが、検討当時のベンチマークでは最高性能に近く、GPUを使用しない予定だったのでNGTを選択しました。
- Annoy(2013-)spotify/annoy
最初期に発表されたライブラリで、性能的には高くないようです。ただしこなれていて使いやすいという声があり、実際に活用している企業もあるようです。 - NMSLIB(2013-)nmslib/nmslib
GPUを使わない前提だと速いらしいです。- 事例は見つけられず
- NGT(2016-)yahoojapan/NGT
検討当時のベンチマークでは最高性能に近く、GPUを使用しない予定だったのでNGTを選択しました。 - FAISS(2017-)facebookresearch/faiss
GPUを使うので高速らしいです。事例を紹介しているBASE開発チームブログさんが、NGTからFAISSに乗り換えたとあるので気になっています。インデックスファイルのサイズが難点だったとありました。 - ScaNN(2020-)google-research/scann
2020年6月に公開されたばかりの最後発です。パフォーマンスが非常に高いらしいです。- 事例見つからず
NGTの使い方
OPTMSでのNGTの使い方について説明します。
(再)ビルド
NGT自体はC++で書かれていますが、Pythonのラッパーが存在します。pip でインストールすることもできますが、性能的に気になる点(共有メモリ使用)オプションがあったため、ビルドしなおして使っています。
Shared memory use The index can be placed in shared memory with memory mapped files. Using shared memory can reduce the amount of memory needed when multiple processes are using the same index. In addition, it can not only handle an index with a large number of objects that cannot be loaded into memory, but also reduce time to open it. Since changes become necessary at build time, please add the following parameter when executing "cmake" in order to use shared memory.
$ cmake -DNGT_SHARED_MEMORY_ALLOCATOR=ON ..
インデックスとIDの紐づけ
NGTのPythonラッパーに検索対象のobject(ベクトル)を登録すると、NGTが採番したIDを返却してきます。検索結果もこのIDが返ってくるのですが、このIDはNGTの都合で決められるものなので、記事を管理している本来のIDと紐づけておく必要があります。そのため、OPTMSではNGTのPythonラッパーをさらにラップしてID変換機能を持たせています。
NGTの使い方
from ngt import base as ngt import random dim = 10 objects = [] # 検索対象 for i in range(0, 100) : vector = random.sample(range(100), dim) objects.append(vector) query = objects[0] # 検索条件(検索対象と同じ次元のベクトル) index = ngt.Index.create("tmp", dim) index.insert(objects) # インデックスに登録。登録したIDのリストが返却される index.save() result = index.search(query, 3) # 類似するベクトルを3件抽出 for i, o in enumerate(result) : print(str(i) + ": " + str(o.id) + ", " + str(o.distance)) object = index.get_object(o.id) print(object)
ここまでのまとめ
ブログの記事を書くときにどんな画像をアイキャッチに使うか悩んだ経験があるので、記事に合う画像を見つける機能は便利だと思います。今後の課題としては、キーワードに頼らずに画像そのものの特徴を使うことです。
おわりに
これまで3回に分けて、記事や画像のリコメンドエンジンの中身と開発までの道のりを説明しました。ここで完成ではなく、まだ入り口に立った段階です。最後に今後の課題をまとめておきます。
- ユーザー操作を通じて推薦に影響を与える
- ユーザーとの対話的なUIを通じてオウンドメディアの方針、例えば読者のイメージを指定する
- 推薦した記事を購入候補に加えた、など暗黙的な操作
- オウンドメディアやその読者の傾向を可視化する
- 当社のもつ消費者価値観モデル(Societas)などの応用
- 同業種あるいは異業種のオウンドメディアと比較できると良い
- オウンドメディアのトラッキングデータを使って、ライセンスドコンテンツのパフォーマンスを最大化する
- トラッキングの仕組みは当社から提供済み
- オウンドメディア単体ではなくインターネットのトレンドを考慮する
- キーワードの示唆を与えるなど
以上に加えて、ユーザーからの意見も取り入れて進化していかなければなりません。今後も機会があればその過程を報告したいと思います。