
これは当社がリコメンドエンジンを提供しているOPTMS CONTENT(以下OPTMS)のアルゴリズムを解説する記事です。今回を含めて全3回の連載を予定しています。
今回はOPTMSというプロダクトの概要と、基本的なアイデアを説明します。
 西尾 義英(ニシオ ヨシヒデ)
西尾 義英(ニシオ ヨシヒデ)データを活用できる製品・基盤づくりがテーマです。
プロダクトの概要
OPTMS CONTENT とは
OPTMS CONTENTは、成果予測AIで“最適化されたコンテンツ”(=オプティマイズド・コンテンツ)を提供する、リコメンデーション・プラットフォームです。
一言でいうと、ライセンスドコンテンツを販売するプラットフォームです。ライセンスドコンテンツとは、新聞や雑誌などのメディア企業が専業メディア以外の企業サイト(オウンドメディア)に転載を許可した記事(一部画像も含む)のことです。
記事をライセンスするというビジネスモデルにはなじみがないかもしれません。コンテンツマーケティングの課題はオウンドメディアに掲載する記事の量と質を両立することと言われますが、ライセンスドコンテンツは記事の量を増やす手段として考慮すべき選択肢となっています。
ライセンスドコンテンツが得意とするのは、業界のトレンドなど広く読者を集めるための記事を用意することです。そちらは一定の質が保証されたライセンスドコンテンツに任せることで、記事執筆のリソースを自社の深い専門領域に集中することができるようになります。ただし、大量のライセンスドコンテンツの中からどのような記事を掲載するかの選定は重要で、従来は専門家によるコンサルティングを必要としていました。OPTMSはここをリコメンドエンジンに任せることで、ライセンスドコンテンツ活用のハードルを下げることを狙っています。
サービス提供形態
OPTMSとは株式会社アマナ(以下アマナ)が開発・販売するプロダクトです。私たちはコンテンツの推薦機能をAPIとして提供しています。

ライセンスドコンテンツは当初海外の記事のみをNewsCred*1から提供されていましたが、アマナによって国内出版社との契約を拡げているところです。国内向けのオウンドメディアであれば海外記事は翻訳が必要ですが、翻訳の手配もOPTMSから行うことができます。
記事にはしばしばアイキャッチ用の画像が添えられています。元記事で使われていたものが利用できる場合もありますが、株式会社アマナイメージズで販売されているストックフォトの一部をOPTMSを通じて購入できるようになっています。画像の価格が記事にインクルードされている、実質無料の画像もあります。リコメンドエンジンは画像の推薦も行っています。
開発にいたった経緯
企業と顧客の間の最適なコミュニケーションをデザインする。この課題を共有する多業種多企業が結集し、共に解決策を探っていくR&Dプロジェクトが「価値観・HI コンソーシアム」です。
~当社プレスリリースより~
私たちはマーケティングコミュニケーションの最適化を目的とした研究開発活動を行ってきました。特にコンテンツの自然言語処理と、消費者の価値観を定量化する技術に注目しており、以下をリリースしています。
- iNSIGHTBOX
メールのクリックや購買のデータを自然言語処理によって解析することでコンテンツ制作の支援やターゲティングを行うことのできるプロダクト - Societas
消費者の価値観を分析する独自のフレームワーク
その後、2017年にはアマナと私たちを含む4社で「価値観・HIコンソーシアム」を立ち上げ、映像・画像・文章などのクリエイティブを顧客の価値観に合わせる手法の共同研究を行っていました。同時期に、アマナにてコンソーシアムとは独立してOPTMSの企画が進められていたところ、「価値観・HIコンソーシアム」でのつながりから、私たちも開発に協力させていただくこととなりました。
プロトタイピング
OPTMS が提供したい推薦とは
OPTMS CONTENTは、企業やブランドのマーケティング戦略やコンテンツのパフォーマンスデータに基づき、あなたのブランドやサービスとのマッチ度(COR -Content Optimized Rate-)の高いコンテンツをリコメンドします。
OPTMS の特長は購入する記事を推薦するという点です。リコメンドエンジンに求められることは大きく2つあります。
- 掲載するオウンドメディアのコンセプトにあった記事である
- ターゲット読者が興味を持つ話題か
- ブランドや企業が伝えたいことに関連するか
- オウンドメディアの成果が上がるような記事である
- 広く読者を集める
- オウンドメディア内の回遊を増やす
- 最終的に問い合わせなどの行動につながる
また、コンテンツは記事だけでなく画像もあります。記事の内容と関連し、サイトの雰囲気とも合う画像を選ぶ必要があります。
方針
コンテンツを推薦する手法はいくつもありますが、提供先のサービスによって使えるものもあれば使えないものもあります。
OPTMSにおいては、ユーザーが記事を採用するのはそれぞれ自社のオウンドメディアに掲載するためであり、同じ記事が複数のメディアに掲載されることは避けたいことです。言い換えると、他ユーザーが購入した記事を参考にする、いわゆる協調フィルタリングは使えないということです。また、コンテンツのパフォーマンス、つまり採用した記事に対する読者の反応データを活用する目論見があるものの、ローンチまでは検証できませんし、各ユーザーの導入直後はいずれにしてもデータがありません(コールドスタート)。記事のパフォーマンスデータが得られない状態でも成立する手法が必要でした。
取れそうな選択肢は、ユーザーのオウンドメディアに掲載された記事と近しい記事を推薦することです。まだオウンドメディアを持たない、サイトをこれから立ち上げるというユーザーの場合は、ベンチマーク先のサイトを探して代用すれば良いでしょう。この方針(内容ベースの推薦)でリコメンドエンジンを実装可能か、プロトタイプを作ることからはじめました。
記事のベクトル化
内容ベースの推薦を行うために、まず記事同士の「類似度」をどのように定義するかを考えます。これは、古典的には文書に現れる単語の出現頻度によって文書を数値(ベクトル)に置き換え、ベクトル同士の類似度を計算するという手順で実現できます。この方法はベクトルが語彙数と同じ程度に高次元となってしまい計算が難しいという問題があり、近年はWord2Vecなど単語や文書を数百次元のベクトルに変換する「Embedding(埋め込み)」という技術が良く用いられるようになっています。Word2Vecは単語をベクトルに変換することですが、文書全体にわたって平均を取るなどすれば文書のベクトルも得られます。OPTMSでは、以下の手法を採用しました。
- 準備:
- 単語ベクトルを得る学習済みモデルを入手 → cawl-300d-2M@fasttext
- 300dとはベクトルが300次元であること、2Mは学習した単語数が約200万であることを表す
- ライセンスドコンテンツに出現する単語のdf(単語がいくつの記事に含まれるか)を計算しておく
- 単語ベクトルを得る学習済みモデルを入手 → cawl-300d-2M@fasttext
- ベクトル化:
- 日本語の記事は英語に機械翻訳する(今のところライセンスドコンテンツのほとんどが英語記事のため)
- crawl-300d-2Mを記事中の単語に適用して、単語ベクトルを得る
- 記事中の単語に対するtf-idfを計算して、2.の重み付き平均を取る
データの集め方
プロトタイピングを始める時点では、NewsCredからの記事提供基盤が完成しておらず、記事データセットの全体像がつかめていませんでした。また利用するユーザーの想定もできていなかったので、アマナに以下2点を協力いただきました。
- サンプル記事として、ライセンス元メディアで公開されている記事URLを約3000件、なるべく幅広いジャンルからリストアップ
- OPTMSを利用してほしいユーザー企業を数件仮定し、公開中のオウンドメディアをリストアップ
記事本文は、1の記事URL、および2のサイトから記事一覧ページを探しURLのリストを得てからスクレイピングしました。手間こそ掛かりましたが、推薦したいアイテムがインターネットに公開されている情報のため、データ収集難易度は低かったと言えます。
プロトタイプの振る舞い
プロトタイプはRのShiny を使って作成しました。プロダクトの実装はPythonを使っていますが、筆者はRの方が慣れていたためです。Shiny とは、データ分析結果のグラフや表をインタラクティブに操作するWebアプリケーションを作れるというライブラリです。内容ベースの推薦がどのように仕組みか関係者に説明したかったので、これを視覚的に見せつつ、使い方が想像できるようなインタフェースも仮組みしています。
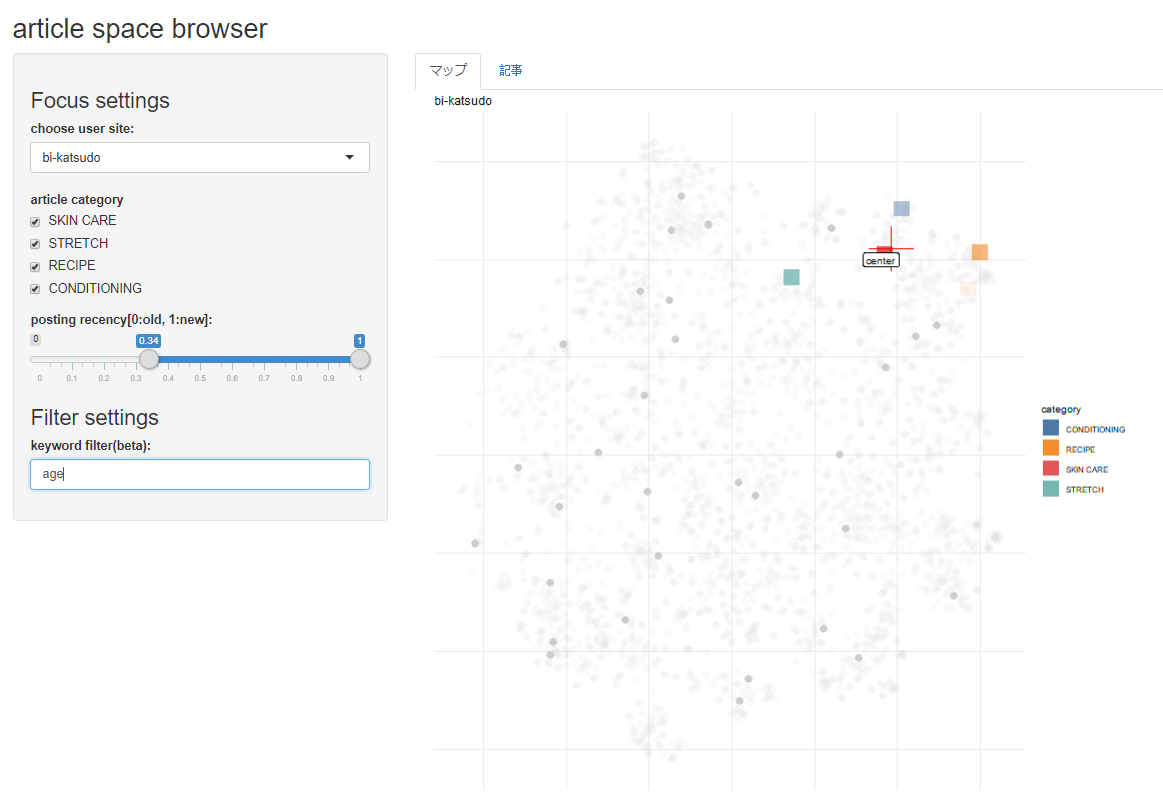
さて、記事を推薦する基本的なアイデアとは、まず仮想ユーザーのオウンドメディアからクロールした記事の中心を計算し、次にそれを基準点としてライセンスドコンテンツのサンプル記事のベクトルとコサイン類似度を計算し、最後に類似度が高い順に並べるというものです。
「マップ」タブにはあらかじめサンプル記事を散布図として表示してあり、ここにクロールした記事を重ねて表示します。クロールした記事はサイト固有のカテゴリと、記事の公開日の情報を持っており、これを横のパネルで条件指定することで推薦に用いる記事が増減し、中心点(赤い十字にcenterのラベル)が動きます。中心点が動くと推薦結果が変わります。タブを「記事」に切り替えるとこの時推薦される記事がリストアップされます。

記事の横に表示されているのは、記事にもともと使われていた画像です。プロダクトではストックフォトから記事に合うものをマッチングさせていますが、プロトタイピング時点では後回しにしています。
ここまでのまとめ
データに基づくプロダクトの振る舞いはなかなか人に説明しづらいので、目に見えて動くものを作ることが重要だと思います。仮のデータを使い、推薦アルゴリズムも単純なものでしたが、プロジェクトメンバーから好評を得られたので、自信をもって先へ進めることができました。データが無い状態でプロジェクトが始まることも意外と多いので、どうにか別の方法で集めてくるということも学びました。
プロダクトにおいて工夫した点や今後の課題については次回以降の記事で述べたいと思います。