AWS Step Functions(以下 Step Functions) で不特定の Task を起動し、その結果を集約する方法を検討します。AWS で Step Functions を始めとするマネージド・サービス を組み合わせたワークフローを作成するにあたって、不特定多数の Task を起動する仕組みと、1対1で非同期呼び出しをし完了時にコールバックする仕組みは存在しますが、組み合わせるには若干工夫が必要でした。本記事で検討した方式を使うことで、処理の流れは固定しながら処理のバリエーションを追加しやすくなります。
 西尾 義英(ニシオ ヨシヒデ)
西尾 義英(ニシオ ヨシヒデ)データを活用できる製品・基盤づくりがテーマです。
問題設定
今回検討する動機となった問題について概要を説明します。下図は複数のサブシステムへS3バケットへのデータ出力を指示し、結果を集約・加工するワークフローを表します。
- 集約側を Integration、サブシステムを SubsystemA,B とする
- Integration と SubsystemA,B はそれぞれ独立した Stackにデプロイされる SAMアプリケーション

Force
実現にあたっての制約は以下の通りです。
- TaskA, TaskB のARN、データの出力先バケット名 ExportBucketA や ExportBucketB を Integration が事前に知らないことにする
- SubsystemA や B は Integration とは別 Stack である。Integration デプロイ時には存在しないかもしれない
- 逆に Integration で定義したリソースを SubsystemA,B が参照するのはアリとする
- SubSystemA と SubSystemB の実行順序は問わない
Fan-out / Fan-in パターン
この問題は Fan-out/Fan-in パターンと呼ばれることがあります。Fan-out とは不特定多数の処理を起動することで、Fan-in はそれら処理結果を受け取ることを指す言葉です。AWSでは、SNS などを使って Fan-out を実装することができます。逆に Fan-in については直接サポートする方法が見つかりませんでした。
Fan-in の実現例として、起動した処理の状態をデータベースに書き込み、全ての処理状態が完了するまで呼び出し側で待機するという方式があります。これは処理を起動する側がどんな処理を実行するかを管理することであり、制約を満たすことができません。Fan-out 先である SubSystemA や SubSystemB に、 Integration が依存しないようにすることが難しいポイントだといえます。
ところで、 Step Functions では TaskToken を用いたコールバックがサポートされています。言い換えるとFan-out 先が一つに限定できる場合は、SNS などを使うことで処理の実体に依存せずに処理を起動し、その結果を受け取ることができることがわかります。
つまり、Integration が起動したい 複数の処理を 動的に参照する方法が必要です。
提案法
Integration は「求人」を出し、SubSystemA や SubSystemB がそれに「応募」するというメタファーを考えます。処理のシーケンスを図に示します。「求人」には SNS を使い、「応募」先は S3 バケットとします。ここに Integration から呼び出してほしい Lambda の ARN を書き込む作戦です。
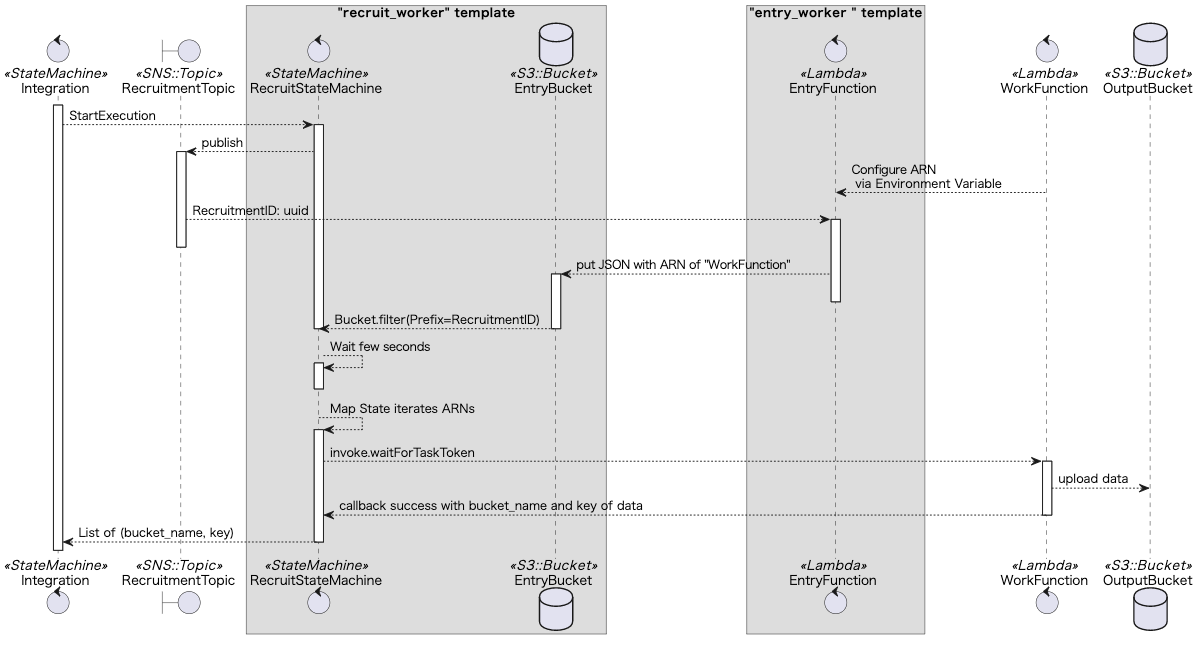
RecruitStateMachine のグラフ構造
RecruitStateMachine のワークフローを可視化したものが下の図です。
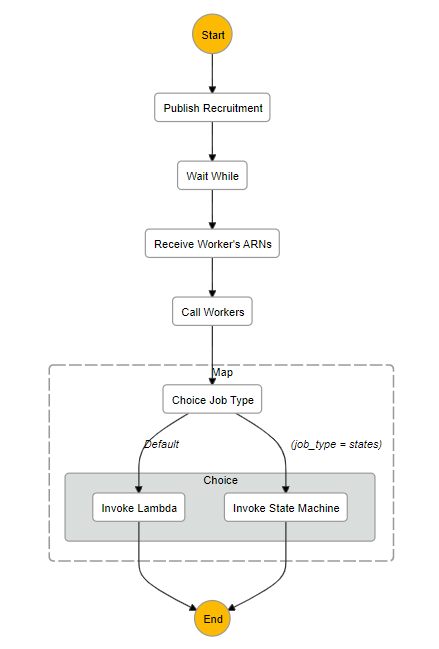
| Task Name | Type | Description |
|---|---|---|
| Publish Recruitment | Task | 処理の実体(ARN)を募集する |
| Wait While | Wait | 募集に反応したLambdaがS3バケットに書き込むのを待機する※1 |
| Receive Worker's ARNs | Task | S3バケットに書き込まれた情報を読み出して後続処理に流す |
| Call Workers | Map | ARNごとに以下を実行: |
| └ Choice Job Type | Choice | Lambda または StateMachine の場合分け※2 |
| ├ Invoke Lambda | Task | Lambda を非同期に呼び出し |
| └ Invoke State Machine | Task | StateMachine を非同期に呼び出し |
議論
提案法に対する懸念点や代替案・拡張について検討します。
応募先はS3バケットで良いか?
「応募」先として最初に考えたのは SQS を使うことです。いろいろ検討するうちに、キュー内の重複や異常発生時にキューをクリアする必要があるなど、気になることが増えたので S3 バケットを使うことにしました。
EntryFunction の応答が返ってこなかったら?※1
RecruitStateMachine の Wait While で10秒待つことにしていますが、Lambda の応答時間が保証されている訳ではないので不安が残ります。EntryFunction の中身は所定の S3 バケットに小さな JSON を書き込むだけなので1秒未満で完了するようです(Python 3.8ランタイム、 128MBメモリー)。Lambda のタイムアウトを待ち時間より十分短くしておくと異常検知できるかもしれません。
あるいは、RecruitmentTopic の Subscription を調べると応募数の上限を知ることができます。むしろ、SNS Topic と Subscription を宣言だけしておいて(実際にはメッセージを送ることなく)Subscription のエンドポイント(プロトコルがLAMBDAの場合、メッセージを受信する Lambda の ARN)を直接起動するという手段も考えられます。ただし、SNS メッセージフィルターなどを使って、状況に合わせて応募を見合わせるという選択が取れないのは不自由かも知れません。
Lambda または StateMachine を起動したい※2
筆者のプロジェクトでは 処理の実体が StateMachine になる場合があります。当初 Lambda から StateMachine を呼べば良いと考えていましたが、Step Functions のコンソールから処理の状態を見ていく時に、Lambda から StateMachine の呼び出しを追うことができないため、直接 StateMachine を起動することができるようにしました。具体的には ARN と共に job_type というプロパティを持ったJSONを書き込むようにします。
テンプレート化
図 で "recruit_worker" や "entry_worker" とした部分を別の SAM template に切り出しておくと、処理の依頼側と実行側の組み合わせが違ってもテンプレートや定型処理をコピペしなくてすみます。通知のための SNS Topic は処理の依頼側が変われば都度別のものを定義し、パラメータストアに公開しておきます。実行側はこの SNS Topic をパラメータストア経由で動的に参照することで、依頼側の求人に任意の Lambda を紐づけることができるようになります。
おわりに
不特定多数の処理を起動しつつその結果を集約するというのはニーズが低いのか、現在のところ直接的なサポートが見つからない状況でした。今回検討した方式により
- サブシステム の種類が増えても Integration を更新する必要がない
- 例えば、マルチテナントでテナントごとにデータ連携先(入力・出力)が異なる場合、連携先ごとにサブシステムを定義し、サブシステムそれぞれが起動すべき状況を判断する
といった柔軟性を得ることができます。また Step Functions の Task 間を流れる情報が JSON としてコンソールから確認できるので、処理の見通しがしやすく気に入っています。ただ議論で触れたように Lambda の実行が短時間に完了しない懸念もあり、引き続き改善を検討したいと思います。