はじめに
私は書籍を全文検索するために、OCRでテキスト化を行なっています。
コストの面から、個人利用無料のYomiTokuというローカルOCRを使っていますが、どの程度の精度なのか知るために、簡単に他のOCRモデルと比較してみました。
TL;DR(3行まとめ)
- 強いノイズあり → Google Cloud Vision一択(唯一実用レベル)
- 通常の文書 → Azure or YomiToku(最高精度・高速・低コスト)
- OpenAI系 → 今回の日本語OCRでは全般的に不適
比較対象モデル
OCR専用でないものも含めて、以下のモデルを比較対象としました。
- Google Cloud Vision Document AI
- Azure Computer Vision OCR
- YomiToku
- CPU利用
- GPU利用
- Python の Tesseract
- OpenAIのチャットAIモデル
- GPT-4o-mini
- GPT-5
- GPT-5-mini
- GPT-5-nano
OCR 対象データ
読み取られるべき文章が、正確にわからなければ精度を評価できません。 そこで、AI でテキストを生成し、さらに画像化したものをOCR対象としました。
また、画質の影響も知りたかったので、それぞれの画像化テキストにノイズも追加してみました。
テキスト
経験的に、旧字などは精度が低い印象をもっています。 そういった使用される文字の影響を考えて、以下の7種類の日本語テキストソースを用意しました。
| ソース名 | 文体など |
|---|---|
| neko-bunretsu.txt | 普通の小説 |
| neko-rakka.txt | 普通の小説 |
| neko-gaku.txt | 哲学っぽい |
| neko-iri.txt | 旧字・難読語・饒舌体 |
| neko-tsumi.txt | 旧字・難読語 |
| neko-moji.txt | 黒田夏子風 |
| neko-stalker.txt | 舞城王太郎風 |
全て、AIに簡単に特徴を説明して生成させた架空の小説テキストです。 (ソース名にテキストファイル全文をリンクしています)
ノイズ
以下の5種類のノイズを画像に追加しました。
| ノイズ名 | 説明 | サンプル |
|---|---|---|
| none | 無加工 | |
| gaussian | 低画質っぽいノイズ |  |
| speckle | 斑点ノイズ |  |
| salt-pepper | 黒い点が加えられる |  |
| poisson | 人間でもかなり読みにくいノイズ |  |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
評価指標
CER(Character Error Rate)を主な評価指標としました。 レーベンシュタイン距離の各操作の回数を、文字数で割ることで、算出します。 低いほど良い性能を示します。
CER = (置換 + 挿入 + 削除) / 文字数
0であれば、完全一致となります。
なお、レイアウトなどはモデルによって扱いが異なり、今回の興味の範囲にないので、空白や改行を無視して計算しています。
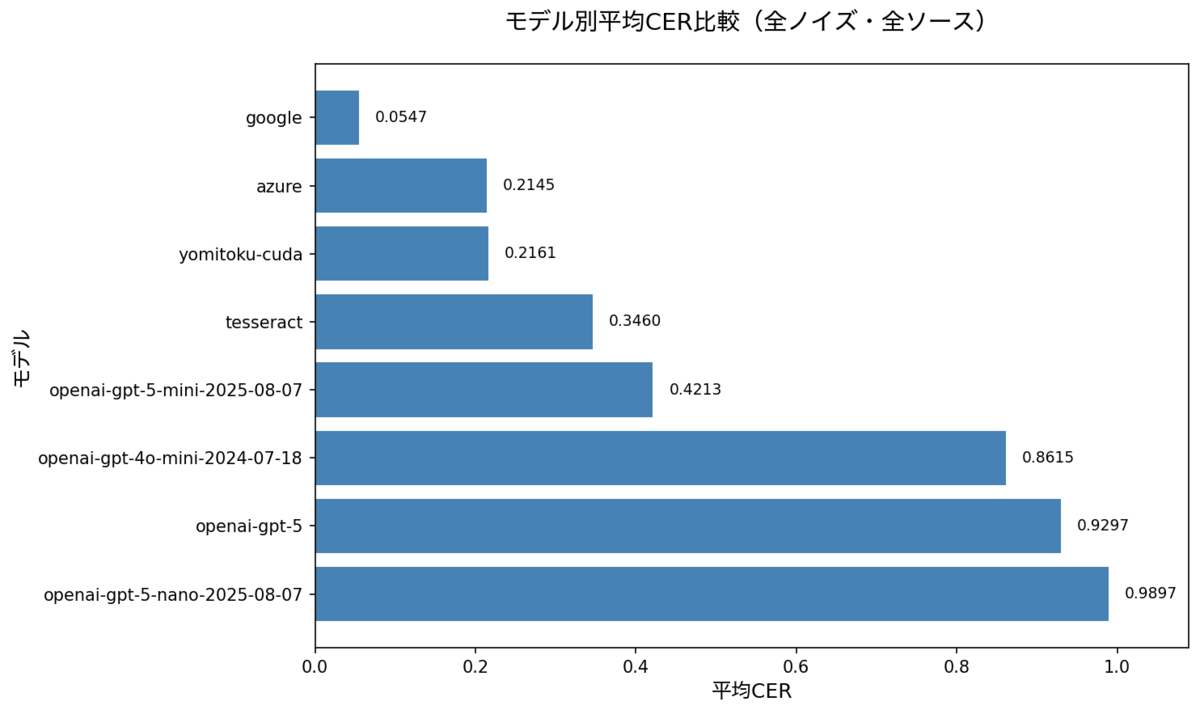
平均 CER 順でのモデル比較(全ノイズ・全ソース)
- google: 0.0547(median 0.0545)。全ノイズで安定して最良。Poissonでも0.0946に踏みとどまる。
- azure: 0.2145(median 0.0108)。Poisson以外は0.018前後と最高だが、Poissonは全件CER=1.0で全滅。
- yomitoku-cuda / cpu: 0.2161(median 0.021)。azureと同様にPoissonで壊滅(~0.99)。GPUとCPUの精度は同じだがGPUの方が速い。
- tesseract: 0.346(median 0.204)。Poissonでほぼ1.0。非Poissonは0.18程度。
- openai-*: mini 0.42、4o-mini 0.86、gpt-5 0.93、nano 0.99と精度が低く、今回の条件では不適。
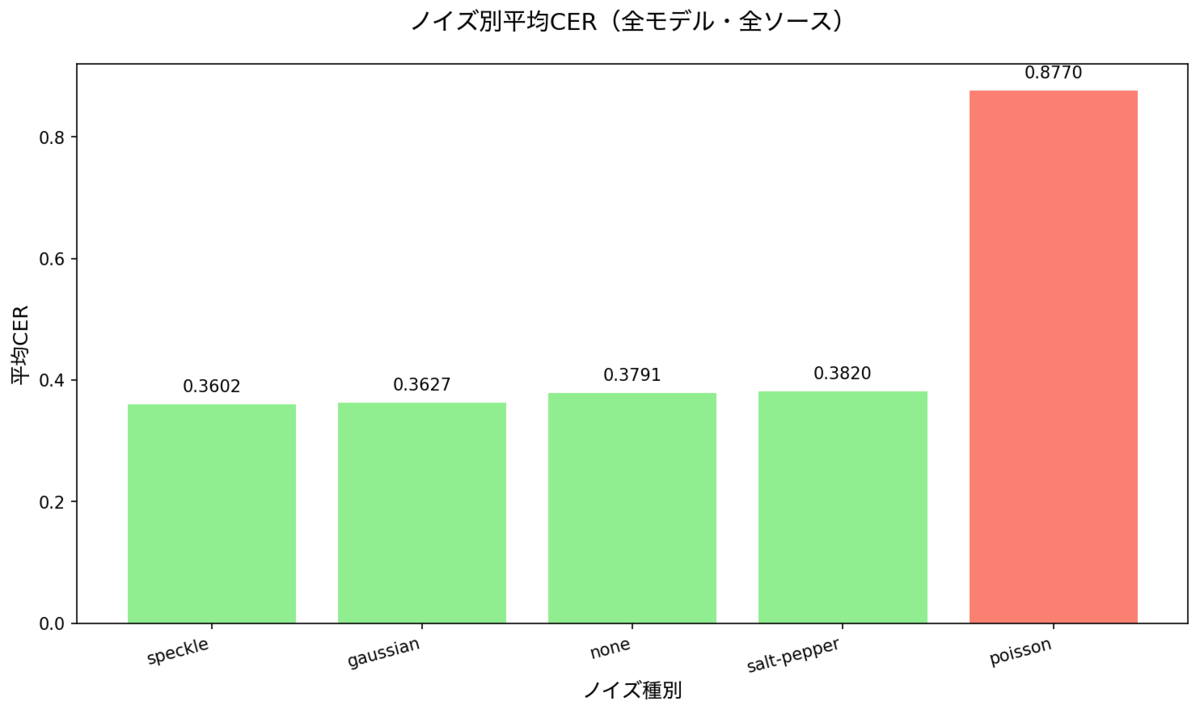
ノイズの影響
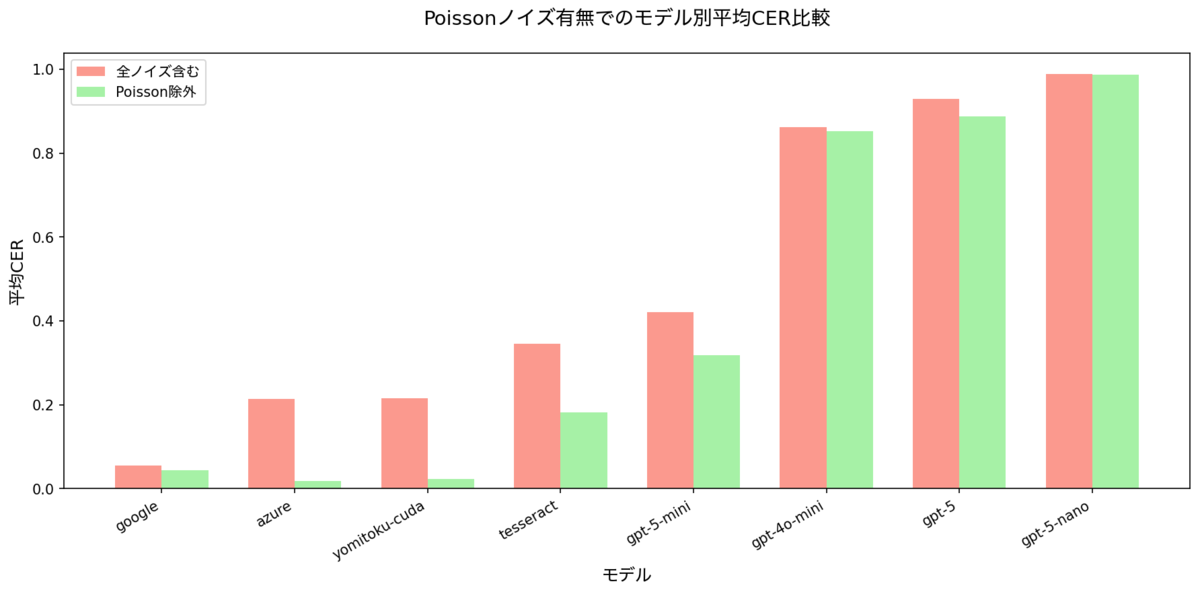
- Poissonが突出して難しく、平均CER 0.877。azure / yomitoku / tesseract / openaiはほぼ全滅。GoogleだけPoissonでも0.04〜0.14程度で踏みとどまる。
- Poissonを除外するとazure 0.0181、yomitoku 0.0229、google 0.0447と、azure/yomitokuが最良。
- 他のノイズ(none/gaussian/speckle/salt-pepper)はモデル順位をほぼ変えず、影響は小さい。
ノイズ別平均 CER(全モデル・全ソース)
Poisson 有無でのモデル比較
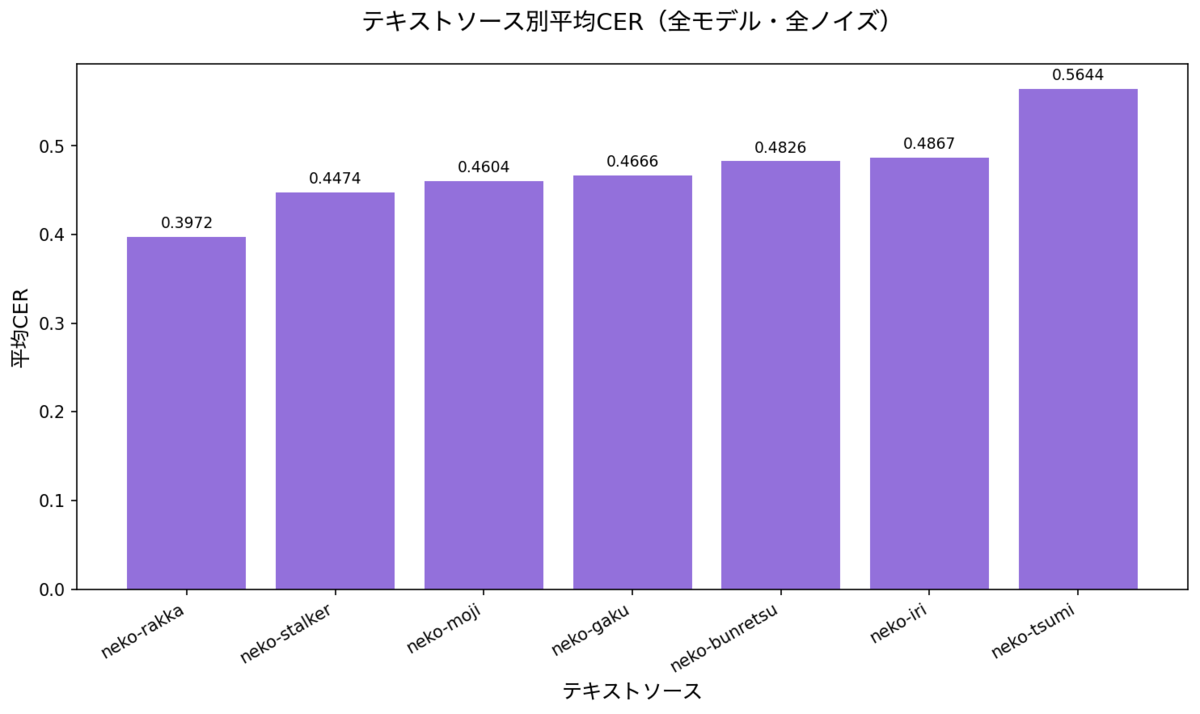
ソースの影響
- 難易度差はあるがPoissonほど極端ではない。平均CER: neko-rakka 0.397(最易)〜 neko-tsumi 0.564(最難)。
- Poissonの失敗がソースに関係なく起きているため、ソース差よりノイズ種の影響が支配的。
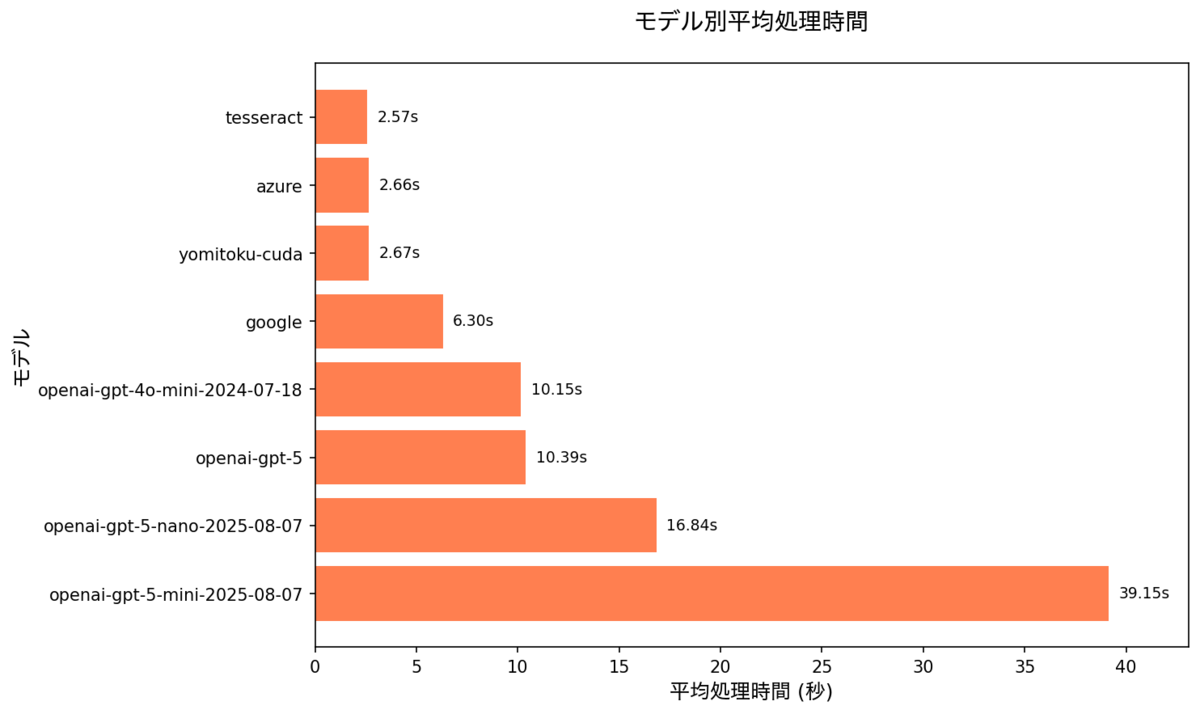
速度
速度: azure や、ローカルの tesseract、yomitoku-cuda が速く、OpenAI系は10〜40sと遅い。
価格
- 価格感: 最安はopenai-gpt-5-nano(0.00072)だが精度が低い。実用域で考えるとAzure/Googleが約0.001前後で安く、OpenAI系(4o-mini/5/5-mini)は0.004〜0.006と高め。yomitoku / tesseractはローカルなので電気代だけとなり、最安の可能性が高い。
- 価格は実際に処理された入出力トークン数に基づいて算出。
| モデル | 平均価格 (USD) |
|---|---|
| openai-gpt-5-nano-2025-08-07 | 0.00072 |
| azure | 0.00100 |
| 0.00150 | |
| openai-gpt-4o-mini-2024-07-18 | 0.00404 |
| openai-gpt-5-mini-2025-08-07 | 0.00523 |
| openai-gpt-5 | 0.00603 |
※ yomitoku / tesseractはローカル実行のため価格を算出していません。
実行環境
- DDR5 96GB
- AMD Ryzen 9 7900X3D
- AMD Radeon RX 7900 XTX (VRAM 24GB)
まとめ
今まで利用してきた経験上もYomiTokuは十分な精度が出ている感じていましたが、今回の結果からも十分使っていけることがわかりました。
- 強いノイズがある/想定される: Google一択(唯一実用CER)。他モデルは前処理(ノイズ除去)を入れない限り不可。
- ノイズが少ない前提: AzureまたはYomiToku(高速で価格が安くCER最低)。Googleはやや遅いが安定志向で選択肢。
- OpenAI系は今回の日本語OCRでは全般的に不適。
今後
今回はできませんでしたが、傾いた文書、手書き、実際の紙などでも試してみたいと思っています。
おまけ

フルスタック調エンジニア。猫を愛し、`npm i -g` を憎む。